Designing jobs - tranforming and filtering data
It's a very common situation and a good practice to design datastage jobs in which data flow goes in the following way:
EXTRACT SOURCE -> DATA VALIDATION, REFINING, CLEANSING -> MAPPING -> DESTINATION
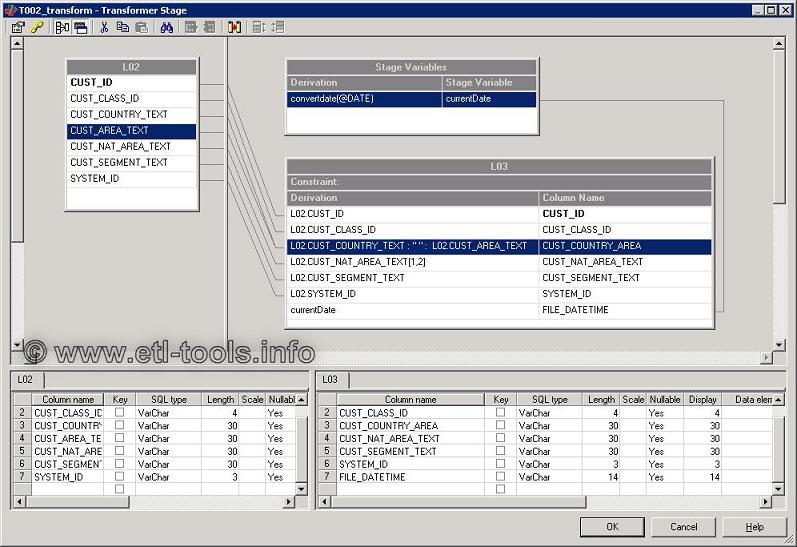
The data refining, validation and mapping part of the process is mainly handled by a transformer stage. Transformer stage doesn't extract or write data to a target
database. It handles extracted data, performs conversions, mappings, validations, passes values and controls the data flow.
Transformer stages can have any number of input and output links. Input links can be primary or reference (used for lookups) and there can only be one primary input and any number of reference inputs.
Please refer to the examples below to find out what is the use of transformers.
In the job design depicted below there is a typical job flow implemented. The job is used for loading customers into the datawarehouse. The data is extracted from an ODBC data source, then filtered, validated and refined in the first transformer. Rejected (not validated) records are logged into a sequential file. The second transformer performs a lookup (into a country dictionary hash file) and does some other data mappings. The data is loaded into an Oracle database.