Processing a header and trailer textfile in Datastage
Example case
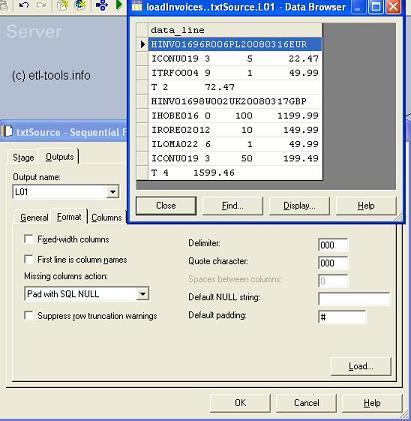
The input file in our scenario is a stream of records representing invoices. It is a text file in a header-trailer format and has the following structure:
- A header starts with a letter H which is followed by an invoice number, a customer number, a date and invoice currency
- Every item starts with a letter I which is followed by product ID, product age, quantity and net value
- And the trailer starts with a T and contains two values which fullfill the role of a checksum: the total number of invoice lines and total net value.
Header and trailer input textfile in Datastage:
Solution
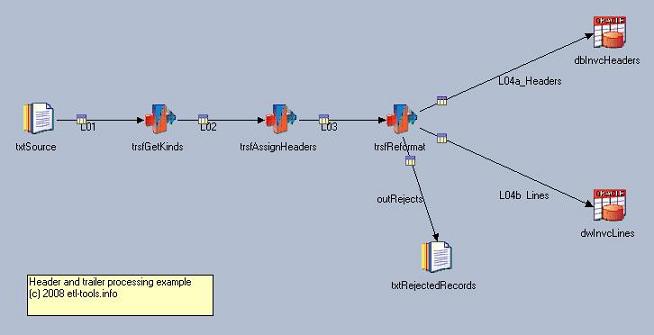
Datastage job design which solves the problem of loading an extract structured into headers and items:
Detailed illustration of each component of the job
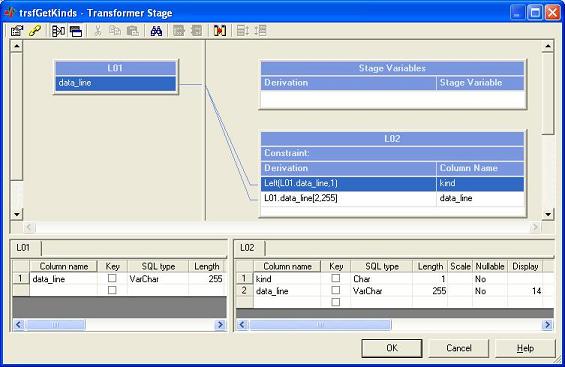
The transformer reads first character of each line to mark records and divide them into kinds:
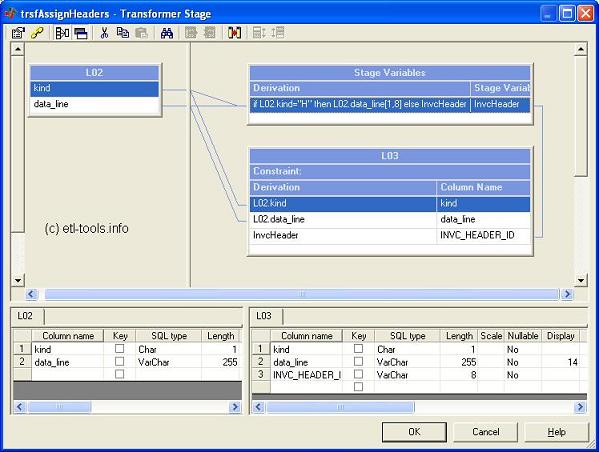
A datastage transformer which assigns headers using a stage variable:
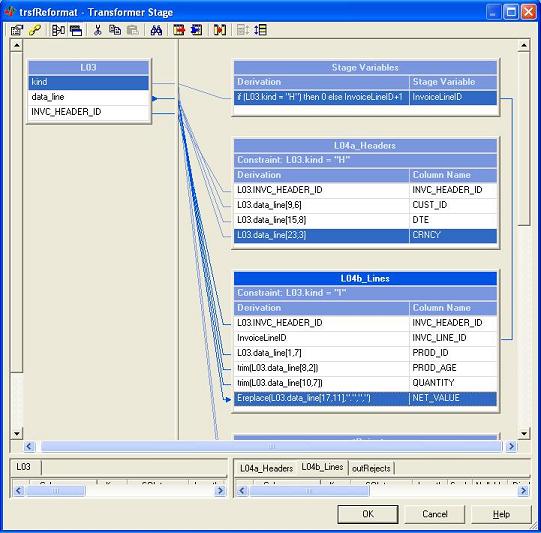
The following transformer splits the flow into headers and items and reformats records into a corresponding structure:
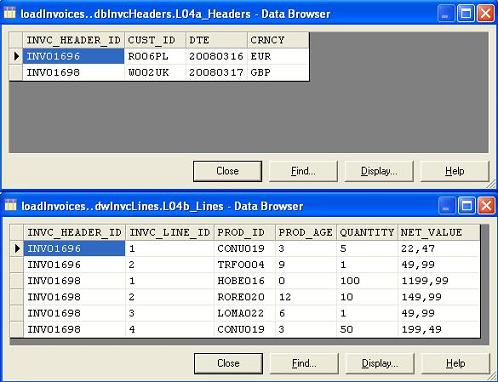
Target oracle tables with correctly loaded invoice headers and lines: