Read kafka queue with ETL Tools
The following article describes real-life use of a Kafka streaming and how it can be integrated with ETL Tools without the need of writing code.
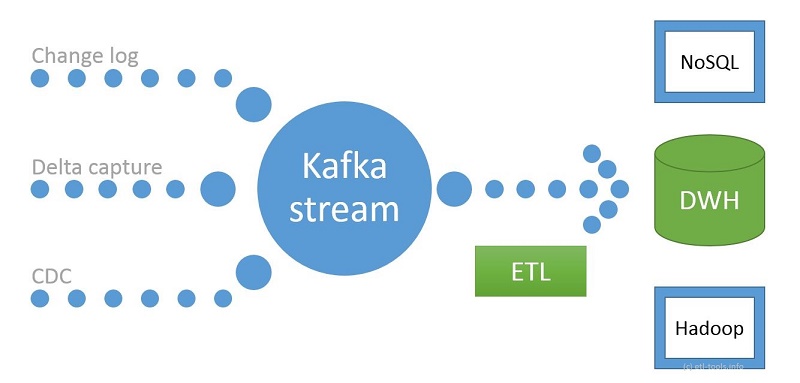
Modern real-time ETL with Kafka - Architecture
The data is delivered from the source system directly to kafka and processed in real-time fashion and consumed (loaded into the data warehouse) by an ETL tool.
The important difference between the streaming approach and traditional ETL process is that all the components are constantly running (active) meaning that it is not trigerred from a schedule.
The source systems are: databases, csv files, logs, CDC which produce kafka messages (so they are active, not just have data available for fetching).
The data is processed with real-time ETL, so there's a requirement for minimum delay between the time when a row appears in the source and is processed into a Data Warehouse.
The data gets loaded into the data warehouse in an incremental way (so only delta records are captured, the history doesn't change and inserts or upserts are performed).
Calculations (aggregations, groupings) are done before writing the data in a Database, the data is stored in a columnar database or NoSQL databse in an ordered manner (Redshift, Cassandra, Couchbase for example). Hadoop HDFS is an alternative target.
The messages are delivered in JSON format (the format of JSON differs accross topic but it contains a header and then actual data). In many cases JSON message might contain hierarchical information so it needs to be flattened in order to be stored in a relational database.
ETL tools capable of reading kafka
Most of the ETL software don't have an option to read or write to Kafka stream in an easy, realiable and solid way, with a few exceptions especially when open source tools are concerned:
For most traditional tools which don't have a native kafka stream connector a custom Java coding is also an option.