Datasets
Managing and operating on large data volumes is usually an extremely complex process. To facilitate that, Orchestrate might extend relational database management system support in Datastage by implementing Datasets.
By and large, datasets might be interpreted as uniform sets of rows within the internal representation of Framework. Commonly, the two types of datasets might be distinguished:
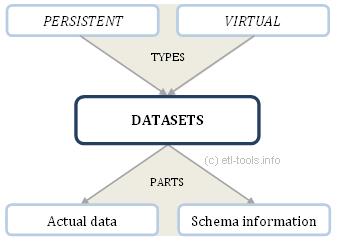
According to the scheme above, there are the two groups of Datasets - persistent and virtual.
The first type, persistent Datasets are marked with *.ds extensions, while for second type, virtual datasets *.v extension is reserved. (It's important to mention, that no *.v files might be visible in the Unix file system, as long as they exist only virtually, while inhabiting RAM memory. Extesion *.v itself is characteristic strictly for OSH - the Orchestrate language of scripting).
Further differences are much more significant. Primarily, persistent Datasets are being stored in Unix files using internal Datastage EE format, while virtual Datasets are never stored on disk - they do exist within links, and in EE format, but in RAM memory. Finally, persistent Datasets are readable and rewriteable with the DataSet Stage, and virtual Datasets - might be passed through in memory.
Accurateness demands mentioning the third type of Datasets - they're called filesets, while their storage places are diverse Unix files and they're human-readable. Filesets are generally marked with the *.fs extension.
There are a few features specific for Datasets that have to be mentioned to complete the Datasets policy. Firstly, as a single Dataset contains multiple records, it is obvious that all of them must undergo the same processes and modifications. In a word, all of them must go through the same successive stage.
Secondly, it should be expected that different Datasets usually have different schemas, therefore they cannot be treated commonly.
More accurately, typically Orchestrate Datasets are a single-file equivalent for the whole sequence of records. With datasets, they might be shown as a one object. Datasets themselves help ignoring the fact that demanded data really are compounded of multiple and diverse files remaining spread across different sectors of processors and disks of parallel computers. Along that, complexity of programming might be significantly reduced, as shown in the example below.
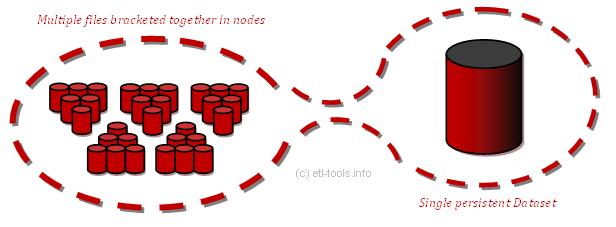
Primary multiple files - shown on the left side of the scheme - have been bracketed together, what resulted in five nodes. While using datasets, all the files, all the nodes might be boiled down to the only one, single Dataset - shown on the right side of the scheme. Thereupon, you might program only one file and get results on all the input files. That significantly shorten time needed for modifying the whole group of separate files, and reduce the possibility of engendering accidental errors. What are its measurable profits? Mainly, significantly increasing speed of applications basing on large data volumes.
All in all, is it worth-while? Surely. Especially, while talking about technological advance and succeeding data-dependence. They do coerce using larger and larger volumes of data, and - as a consequence - systems able to rapid cooperate on them became a necessity.