Processing a header and trailer textfile
Goal
Process a text file which contains records arranged in blocks consisting of a header record, details (items, body) and a trailer. The aim is to normalize records and load them into a relational database structure.
Scenario overview and details
Typically, header and item processing needs to be implemented when processing files that origin from mainframe systems, and also EDI transmission files, SWIFT Schemas, EPIC files.
The input file in our scenario is a stream of records representing invoices. Each invoice consists of :
- A header containing invoice number, dates, customer reference and other details
- One or more items representing ordered products, including an item number, quantity, price and value
- A trailer which contains summary information for all the items
The records are distinguished by the first character in each line: H stands for headers, I for items and T for the trailers.
The lines in a section of the input file are fixed length (so for example all headers have the same number of characters but it varies from items).
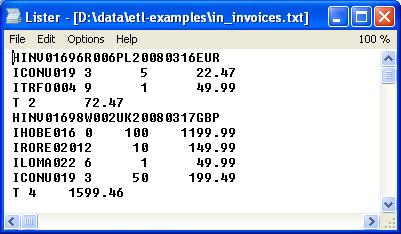
Input data:
- A header starts with a letter H and then contains an invoice number, a customer number, a date and invoice currency
- Every item starts with a letter I which is followed by product ID, product age, quantity and net value
- The trailer starts with a T and contains two values which act as a checksum: the total number of invoice lines and a total net value.
Output data:
Problem solution implemented in various ETL tools: