Kafka - what it is?
Kafka is a streaming (queue-like) platform which is great for building real-time streaming data pipelines and applications. In contrary to traditional ETL Tools it lets process records as they occur and each record contains a key, a value and a timestamp. It is easily scalable, fault tolerant and designed to process huge amounts of data.
Basic terms and concepts related to Kafka
- Kafka Broker = kafka server, kafka instance
- Partition is a registry, an ordered sequence of messages. The historical data can not change, new messages are added to a partition and old messages are deleted. One partition must fit into a server, so usually they are split into smaller pieces. Kafka guarantees good performance and stability until up to 10000 partitions.
- Commit log = ordered sequence of records,
- Message = producer sends messages to kafka and producer reads messages in the streaming mode
- Topic = messages are grouped into topics. Business examples of topics might be account, customer, product, order, sale, etc.
- Producer - there might be many message producers for each topic
- Consumer - all messages are read by each consumer which is listening to a topic
More detailed information about Kafka and architecture concepts can be found on www.confluent.io.
Kafka POC setup tutorial
This tutorial covers a step by step guide on how to set up and start using Kafka for a test POC case scenario in five steps. There's a good documentation on apache kafka website and thousands of online sites elaborating on the details, the focus for this tutorial is to keep it as simple as possible and get it running.
-
Set up configuration for this tutorial:
- Windows machine (a laptop)
- We'll set up a kafka 10.2.1 cluster with two brokers (servers)
- Zookeeper service will be set up to coordinate the brokers and to make sure the state of all the kafka is equal
Kafka POC setup - step by step tutorial
1. Download Kafka
The easiest way to obtain Kafka is to download it from kafka.apache.org/downloads. Select the latest stable binary release.
2. Install
Install kafka by unpacking the tgz file to the local folder (c:\kafka for example)
3. Kafka configuration
Perform Basic Kafka configuration by editing files in config subfolder
- Make two copies of config\server.properties file (server1.properties and server2.properties)
- Edit the following lines in server1.properties and server2.properties:
#set 1 and 2 for each server respectively broker.id=1 # uncomment and set 9092 for server 1 and 9093 for server2 listeners=PLAINTEXT://:9092 # use separate folders for each servers, so subfolder 1 and 2 is defined log.dirs=C:/tmp/kafka-logs/1 #number of partitions per topic, let's have two num.partitions=2
- Edit zookeeper.properties
#set correct dataDir folder dataDir=C:/data/zookeeper
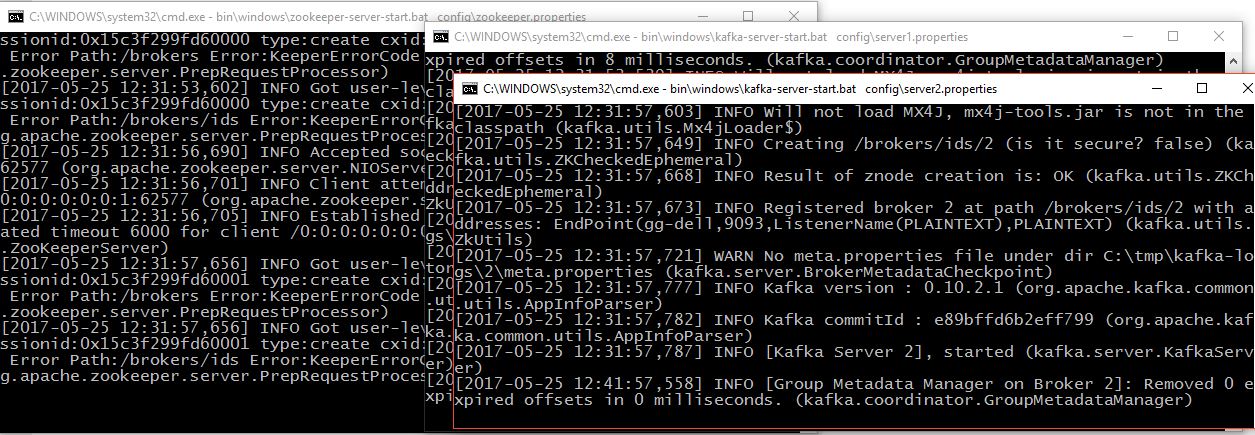
4. Run Zookeeper and Kafka cluster
Note that if the following Java error pops up (Error: missing `server' JVM at ...\bin\server\jvm.dll) you need to create a server folder in jre\bin and copy all files from the client folder.

5. Test
At this point zookeeper and kafka is running and we should be able to perform some tests.
First let's create sample topics using kafka-topics.bat script (for example customer, product, order) on two partitions and with replication factor = 2 (if one server fails, we'll not lose any messages):
Creation of topics should be visible in the console output and also it's interesting to check the log.dirs folder configured earlier.
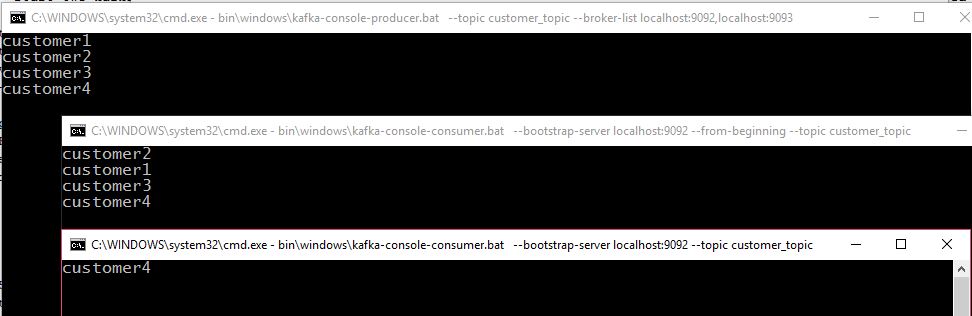
Let's start the console producer and consumer:
Try to write some text in the producer window, if it shows up visible in the consumer shell window, the set up was successful. Now it's good time to do some testing and play around with the environment (f.ex. shutdown one of the kafka servers, see that happens, run a consumer without --from-beginning parameter etc. )
You can also use the following command to describe the kafka topic status: