Spis lekcji:
Implementacja procesu ETL w Datastage do ładowania hurtowni danych
Definincja procesu ETL
Etl jest procesem, w skład którego wchodzą:
- ekstrakcja danych ze źródła operacyjnego danych (np. SAP, PeopleSoft CRM, inny system ERP). Proces ten determinuje bazowe źródła dla hurtowni danych.
- transformacja danych - etap ten może zawierać czyszczenie danych, filtrowanie oraz implementację reguł biznesowych
- ładowanie danych do hurtowni danych bądź bazy danych będącej repozytorium danych dla aplikacji raportujących.
Realizacja procesu ETL w Datastage
W Datastage przepływ danych w procesie ETL jest zarządzany i definiowany w sekwencjach, czyli jobach typu Job Sequences.
Job sterujący (sequencer) posiada interfejs do przekazywania parametrów do jobów kontrolowanych przez niego i umożliwia uruchomienie setki jobów równolegle z żądanymi paramterami. Poza tym zmiana opcji i parametrów środowiskowych (przykładowo przy przenoszeniu projektu ze środowiska testowego do produkcyjnego) jest realizowana w jobach sekwencyjnych i nie wymaga zmiany żadnych ustawień ani rekompilacji jobów kontrolowanych (child jobs).
Joby kontrolowane mogą być uruchamiane równolegle lub sekwencyjnie. Uruchomienie sekwencyjne stosuje się wtedy, gdy uruchomienie kolejnego joba jest zależne od poprawnego wykonania poprzedniego.
Typowy proces ETL w Datastage może być podzielony na kilka segmentów (każdy z tych segmentów może być przetwarzany za pomocą jednego lub wielu jobów Datastage):
- joby pobierające dane z systemów źródłowych - w większości przypadków joby te wykorzystują mechanizmy filtrowania i walidacji danych, jak np. wycinanie zbędnych spacji, obsługę wartości null (zamiana na wartości string), wykrywanie danych które się zmieniły w czasie poprzez czytanie stempli czasowych (timestamps) oraz filtrowanie danych nieistotnych z punktu widzenia hurtowni danych.
- ładowanie tabeli przeszukiwania słowników (lookups) - przeważnie te joby muszą być uruchomione poprawnie aby można było uruchomić przetwarzanie tranformacji. W tym etapie odbywa się ładowane słowników do plików haszujących (lookup hashed files), generowane są sekwencje, dynamiczne klucze główne i ustawiane są różnego typu parametry.
- transformacje - w tych jobach odbywa się najważniejsza cześć przetwarzania danych do hurtowni. Tutaj są ładowane tabele faktów i wymiarów (facts and dimensions).
- joby ładujące ładują przetransformowane dane do hurtowni danych. Często ładowanie typowej hurtowni danych zawiera czynności ładowania (uaktualniania) tabeli faktów i wymiarów, przypisywania kluczy głównych i sekwencji, implementacji SCD (slowly changing dimensions – wymiary wolno zmienne).
Główna sekwencja ładowania hurtowni danych w Datastage
W większości przypadków w projekatch Datastage w przedsiębiorstwach całe codzienne przetwarzanie jest uruchamiane i monitorowane przez jeden główny job sterujący (Job Sequence).
Jest on tworzony i modyfikowany w graficznym środowisku datastage designer w bardzo podobny sposób jak zwykły job serwerowy.
Następujące elementy sekwencji (sequence activities) są szczególnie przydatne i często używane przez joby sterujące:
- Wait for file activity – sprawdza czy istnieje dany plik i jeżeli się pojawi, uruchamiana jest sekwencja
- Execute command – uruchamia komendy systemowe lub komendy datastage shell
- Notification – wysyła informacje za pomocą email z logiem wykonania danej sekwencji jobów. Mail również może zostać wysłany w przypadku wystąpienia błędu w przetwarzaniu. Mail taki może przykładowo trafić do zespołu zajmującego się supportem użytkowników, co pozwoli na podjęcie szybkich działań w celu rozwiązania potencjalnego problemu.
- Exception – wyłapuje wyjątki i często jest używany również z innymi elementami, np. notification activity
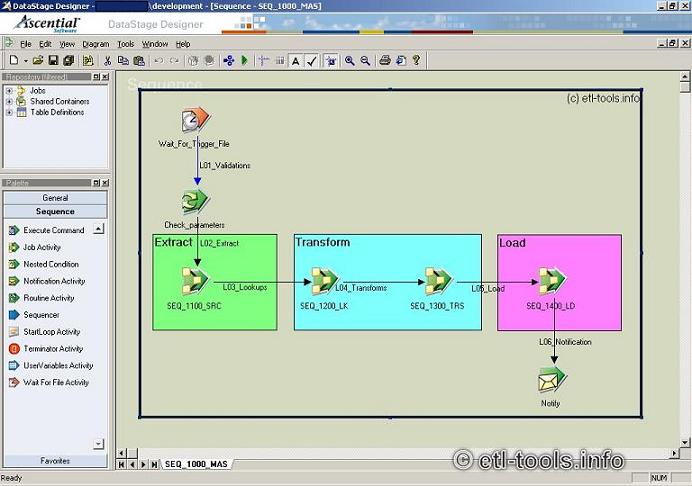
Przykład sekwencji Datastage do załadowania hurtowni danych
Jest dobrą i użyteczną praktyką przyjęcie jednej, spójnej metody nazewnictwa jobów w projekcie. Nazewnictwo jobów z poniższego przyjładu jest jasne, łatwe do sortowania i analizy struktury hierarchii.
-Job główny: SEQ_1000_MAS
--Sekwencje czytające dane źródłowe: SEQ_1100_SRC
----ładowanie klientów: SEQ_1110_CUS
----ładowanie produktów: SEQ_1120_PRD
----ładowanie skali czasu: SEQ_1130_TM
----ładowanie zamówień: SEQ_1140_ORD
----ładowanie faktur: SEQ_1150_INV
--ładowanie kluczy lookup: SEQ_1200_LK
---- ładowanie kluczy lookup: SEQ_1210_LK
--Joby transformujące dane: SEQ_1300_TRS
---- transformacja klientów (tabela wymiarów): SEQ_1310_CUS_D
---- transformacja produktów (tabela wymiarów): SEQ_1320_PRD_D
---- transformacja skali czasu (tabela wymiarów): SEQ_1330_TM_D
---- transformacja zamówień (tabela faktów): SEQ_1340_ORD_F
---- transformacja faktur (tabela faktów): SEQ_1350_INV_F
--sekwencja do załadowania danych do hurtowni danych: SEQ_1400_LD
Sekwencja główna ładowania hurtowni danych może być zaprojektowana jak pokazano na rysunku poniżej (SEQ_1000_MAS).
Sekwencja sie rozpocznie się dopóki nie pojawi się dany plik startowy (WaitForFile activity).
Joby odpowiedzialne za ekstrakcję, transformację i ładowanie będą uruchomione w sposób sekwencyjny i na zakończenie procesu zostanie wysłany e-mail z logiem wykonania.