Struktura blokowa pliku
Cel
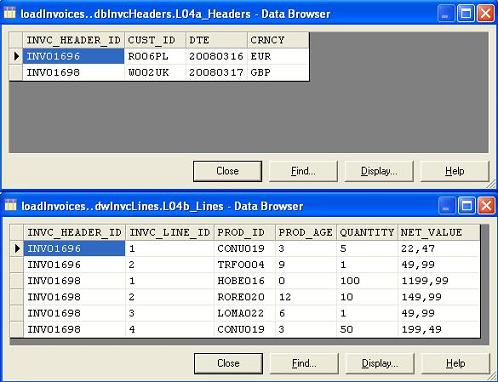
Załadować do dwóch tabel hurtowni danych ekstrakt o strukturze blokowej, składający się z bloków i sekcji zawierających nagłówek, detale i stopkę. Załadowanie pliku polegać będzie na przekształceniu danych z ekstraktu ze struktury blokowej do postaci znormalizowanej relacyjnej bazy danych.
Scenariusz biznesowy
Najczęściej pliki źródłowe w strukturze blokowej generowane są przez systemy mainframe, są to również pliki EDI, EPIC, SWIFT.
Każda faktura składa się z następujących elementów, które mają odzwierciedlenie w strukturze pliku:
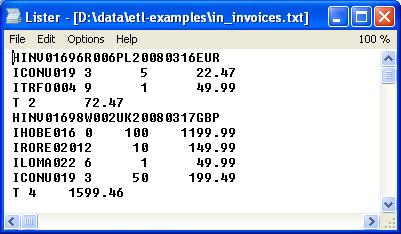
- Nagłówek faktury, który tworzą ogólne dane, które z reguły znajdują się w górnym obszarze faktury. Są to przykładowo id faktury, daty i terminy, kod klienta, dane adresowe sprzedawcy i kupującego i innych szczegółów
- Linie faktury (detale), które zawierają kody zamówionych produktów, ich ilość, cenę, jednostki i wartość
- Podsumowanie (stopka), zawiera dane sumaryczne z faktury. Może się też zdarzyć, że stopka nie niesie ze sobą żadnych informacji, tylko oznacza zakończenie bloku i sygnalizuje przejście do kolejnego elementu.
Poszczególne rekordy są rozróżniane za pomocą pierwszej litery w każdej linii danych. Odpowiednio H odpowiada nagłówkom (header), I liniom faktury (item), a T oznacza podsumowanie (T trailer).
Danych są pogrupowane kolejno w bloki i sekcje. Linie pliku ekstraktu w obrębie danej sekcji mają taką samą ilość znaków.
Dane wejściowe
W niniejszym przykładzie ETL Tools Info plik źródłowy zawiera dane faktur dla klientów. Plik tekstowy w formacie blokowym o strukturze nagłówek-szczegóły.
Struktura pliku jest następująca:
Dane wyjściowe:
Przykładowe implementacje scenariusza (w języku angielskim):
| Powrót do menu Scenariuszy ETL |