Creating transformations in Spoon – a part of Pentaho Data Integration (Kettle)
The first lesson of our Kettle ETL tutorial will explain how to create a simple transformation using the Spoon application, which is a part of the Pentaho Data Integration suite.
The transformation in our example will read records from a table in an Oracle database, and then it will filter them out and write output to two separate text files. The records which will pass the validation rule will be spooled into a text file and the ones that won’t will be redirected to the rejects link which will place them in a different text file.
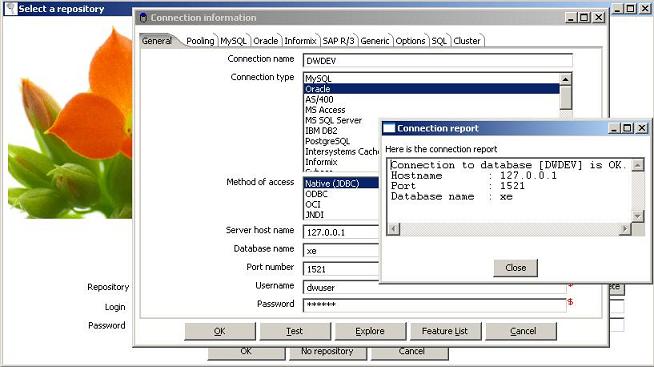
Assuming that the Spoon application is installed correctly, the first thing to do after running it is to configure a repository. Once the ‘Select a repository’ window appears, it’s necessary to create or choose one. A repository is a place where all Kettle objects will be stored – in this tutorial it will be an Oracle database.
To create new repositories click the ‘New’ button and type in connection parameters in the ‘Connection information’ window.
There are some very useful options on the screen, one is ‘Test’ which allows users to test new connections and the other is ‘Explore’ which lets users browse a database schema and explore the database objects.
After clicking the ‘Create or Upgrade’ a new repository is created. By default, an user with administrator rights is created – it’s login name is admin and the password is also admin. It is highly recommended to change the password after the first login.
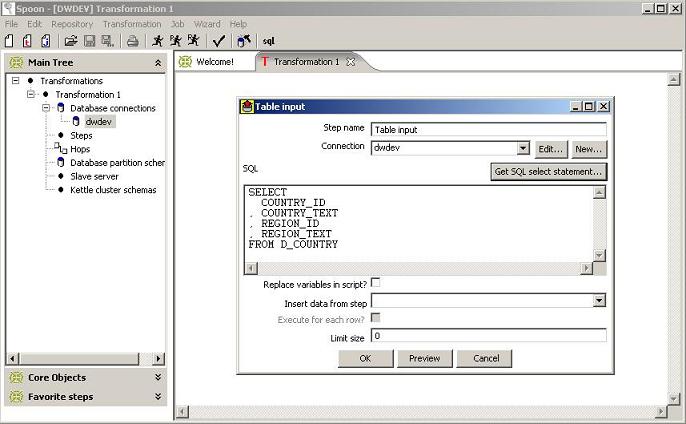
If a connection with repository is established successfully, a Spoon main application window will show up.
To design a new transformation which will perform the tasks described above it’s necessary to take the following steps:
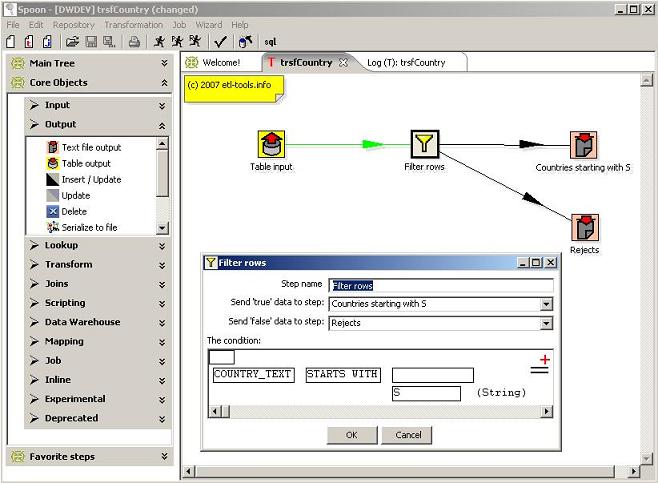
The easiest way to create a Hop is to drag and drop a link between two objects with left SHIFT pressed.
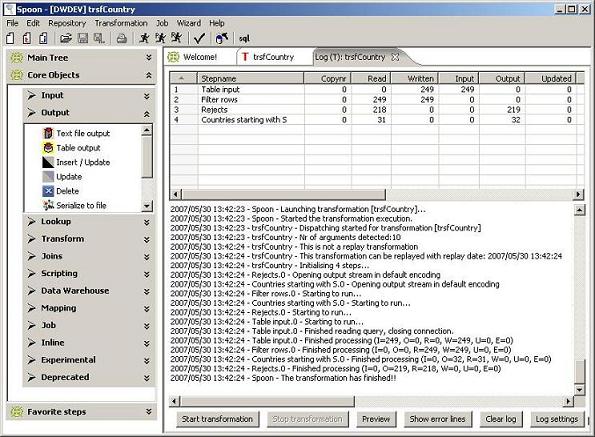
Notice that there are an extra record in both text files. It’s due to the fact that the files are configured to write column headers in the first line.