Kafka Pentaho Data Integration ETL Implementation
Kafka Pentaho Data Integration ETL Implementation tutorial provides example in a few steps how to configure access to kafka stream with PDI Spoon and how to write and read messages
1. Access to Kafka stream
First you need a running kafka cluster. If you want to set up a test POC Kafka server please read this 15 minutes Kafka setup in 5 steps tutorial. Check whether the queue is accessible from the Pentaho ETL machine.
2. Set up Kafka components in Pentaho Data Integration
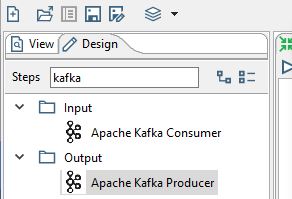
Open up Spoon and go to Tools -> Marketplace. Then select Apache Kafka Producer and Apache Kafka Consumer and install them. After restarting the client two new transformations should appear under Input and Output
3. PDI Transformation to produce sample data
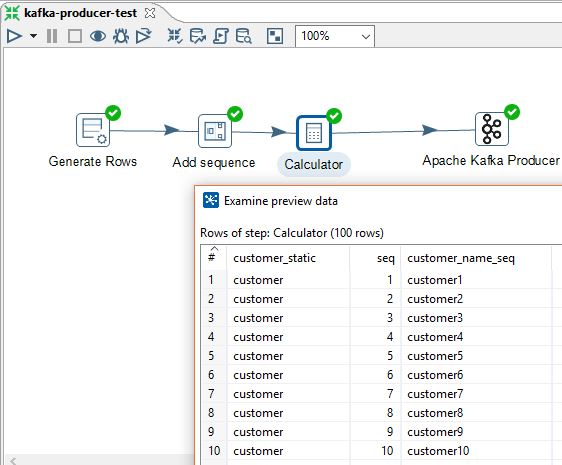
Let's now create a PDI transformation which would produce 100 test messages. It contains a row generator, a sequence is added and then the customer static value is concatenated with a sequence. The transformation and source rows look as follows:
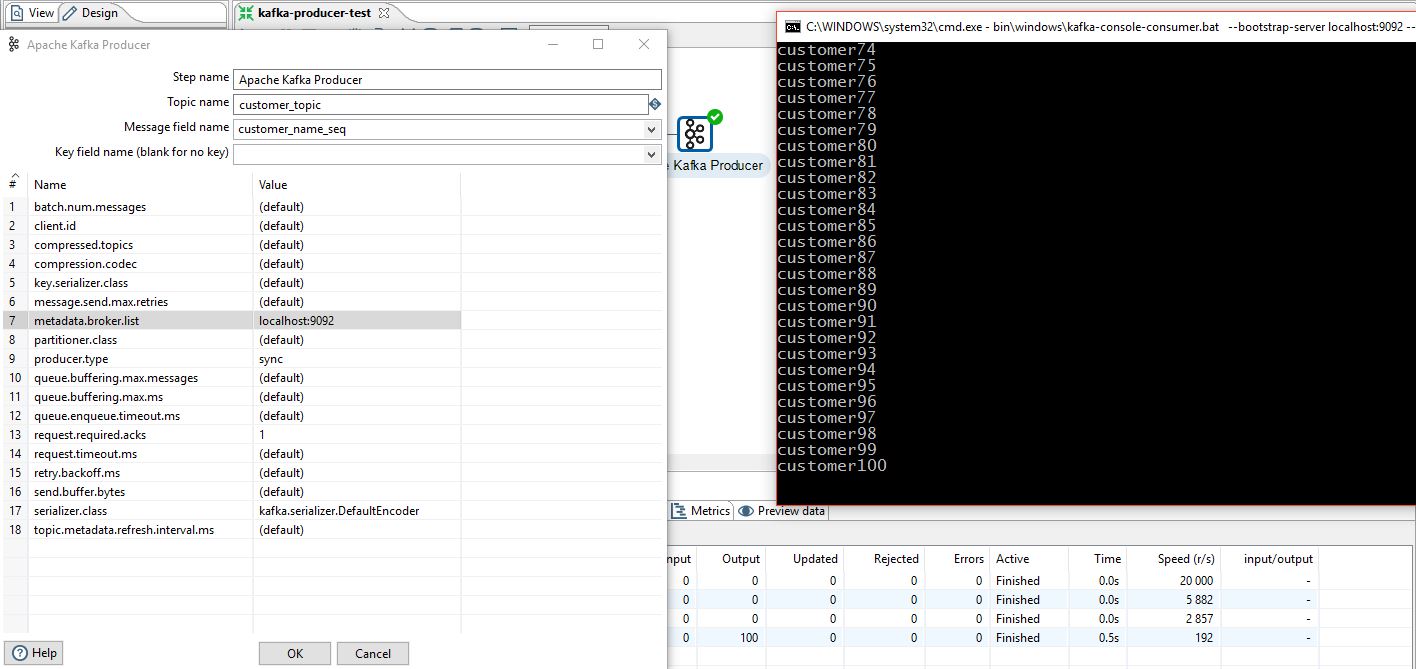
The Apache Kafka Producer is added as an output step. It's important to set the following parameters:
The transformation is ready and can be executed. As we can see in the kafka console consumer window the messages were successfully produced and delivered to the stream.
4. PDI Transformation to consume sample data
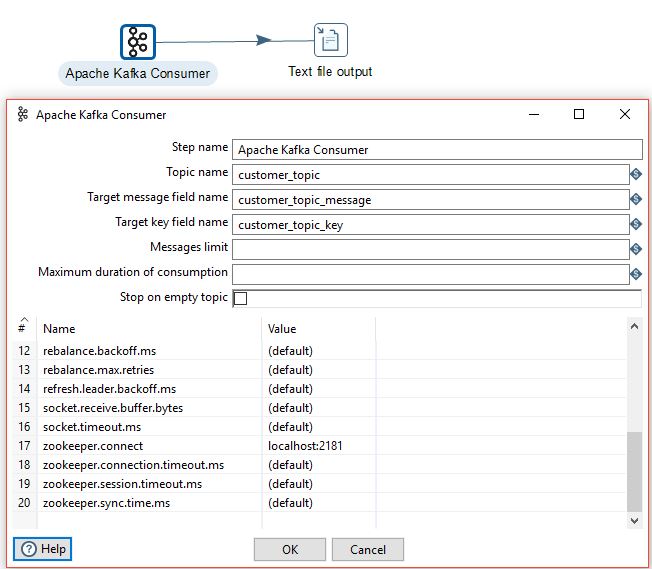
The data is already in the queue, now let's create a Kafka consumer. The first step is to drag Apache Kafka Consumer into a transformation, then double click to set up a few options:
The sample transformation will spool the messages to the CSV file (Text file output step). Note that the transformation is executed and will be running and listening for new messages until maximum duration of consumption is reached (it relates to the duration of the step and not an individual read). As shown in the example below the data is read correctly.
Nest steps would be to produce and consume JSON messages instead of simple open text messages, implement an upsert mechanism for uploading the data to the data warehouse or a NoSQL database and make the process fault tolerant.