Implementing ETL process in Datastage to load a Data Warehouse
ETL process
From an ETL definition the process involves the three tasks:
- extract data from an operational source or archive systems which are the primary source of data for the data warehouse.
- transform the data - which may involve cleaning, filtering and applying various business rules
- load the data into a data warehouse or any other database or application that houses data
ETL process from a Datastage standpoint
In datastage the ETL execution flow is managed by controlling jobs, called Job Sequences. A master controlling job provides a single interface to pass parameter values down to controlled jobs and launch hundreds of jobs with desired parameters. Changing runtime options (like moving project from testing to production environment) is done in job sequences and does not require changing the 'child' jobs.
Controlled jobs can be run in parallel or in serial (when a second job is dependant on the first). In case of serial job execution it's very important to check if the preceding set of jobs was executed successfully.
A normal datastage ETL process can be broken up into the following segments (each of the segments can be realized by a set of datastage jobs):
- jobs accessing source systems - extract data from the source systems. They typically do some data filtering and validations like trimming white spaces, eliminating (replacing) nulls, filtering irrelevant data (also sometimes detect if the data has changed since the last run by reading timestamps).
- loading lookups - these jobs usually need to be run in order to run transformations. They load lookup hashed files, prepare surrogate key mapping files, set up data sequences and set up some parameters.
- transformations jobs - these are jobs where most of the real processing is done. They apply business rules and shape the data that would be loaded into the data warehouse (dimension and fact tables).
- loading jobs load the transformed data into the database. Usually a typical Data Warehouse load involves assigning surrogate keys, loading dimension tables and loading fact tables (in a Star Schema example).
Datawarehouse master load sequence
Usually the whole set of daily executed datastage jobs is run and monitored by one Sequence job.
It's created graphically in datastage designer in a similiar way as a normal server job.
Very often the following job sequencer stages/activities are used to do a master controller:
- Wait for file activity - check for a file which would trigger the whole processing
- Execute command - executes operating system commands or datastage commands
- Notification - sends email with a notification and/or job execution log. Can also be invoked when an exception occurs and for example notify people from support so they are aware of a problem straight away
- Exception - catches exceptions and can be combined with notification stage
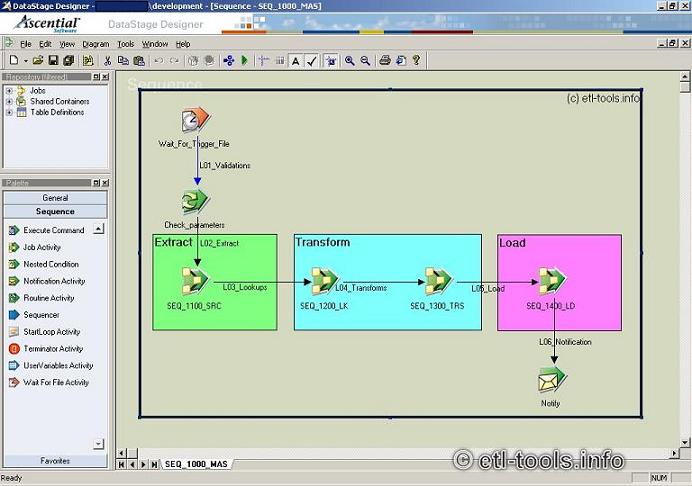
Example of a master job sequence architecture
It's a good practice to follow one common naming convention of jobs. Job names proposed in the example are clear, easy to sort and to analyze what's the jobs hierarchy.
-Master job controller: SEQ_1000_MAS
--Job sequences accessing source: SEQ_1100_SRC
----loading customers: SEQ_1110_CUS
----loading products: SEQ_1120_PRD
----loading time scale: SEQ_1130_TM
----loading orders: SEQ_1140_ORD
----loading invoices: SEQ_1150_INV
--Job filling up lookup keys : SEQ_1200_LK
----loading lookups: SEQ_1210_LK
--Job sequences for transforming data: SEQ_1300_TRS
----transforming customers (dimension): SEQ_1310_CUS_D
----transforming products (dimension): SEQ_1320_PRD_D
----transforming time scale (dimension): SEQ_1330_TM_D
----transforming orders (fact): SEQ_1340_ORD_F
----transforming invoices (fact): SEQ_1350_INV_F
--Job sequence for loading the transformed data into the DW: SEQ_1400_LD
The master job controller (sequence job) for data warehouse load process SEQ_1000_MAS can be designed as depicted below. Please notice that it will not start until a trigger file is present (WaitFoRFile activity). The extract-transform-load job sequences (each of them may contain server jobs or job sequences) will be triggered in serial fashion (not in paralell) and an email notification will finish the process.